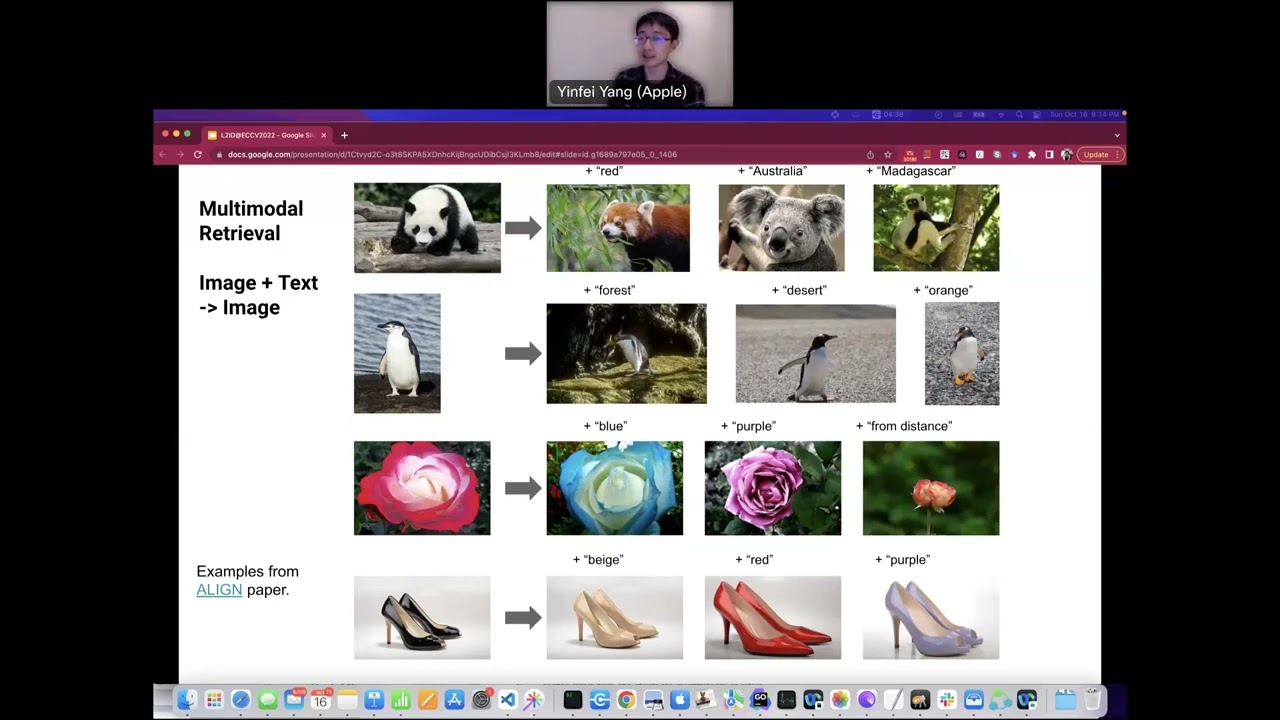
ALIGN: Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision Microsoft Research 57:53 3 years ago 1 946 Далее Скачать
ALIGN: Scaling Up Visual and Vision-Language Representation LearningWith Noisy Text Supervision Stanford Contrastive & SS Learning Group 29:11 3 years ago 1 078 Далее Скачать
Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision Научные семинары по искусственному интеллекту 34:14 3 years ago 110 Далее Скачать
Yinfei Yang: Learning Visual and Vision-Language Model With Noisy Image Text Pairs Learning with Limited and Imperfect Data 22:34 2 years ago 209 Далее Скачать
Scaling Vision-Language Learning to Multiple Languages Kate Saenko 15:15 4 years ago 175 Далее Скачать
Harvard Medical AI: Elaine Liu presents ALBEF – Align before Fuse Vision and Language Representation Harvard Medical AI | Rajpurkar Lab 22:28 2 years ago 1 221 Далее Скачать
【EP3】Large-Scale Visual Representation Learning with Vision Transformers The AI Talks 1:03:21 2 years ago 229 Далее Скачать
【S2E10】Vision-and-Language Alignment - Towards Universal Multimodal AI The AI Talks 34:27 1 year ago 449 Далее Скачать
Harvard Medical AI: Jaehwan Jeong on "Scaling Up Vision-Language Pre-training for Image Captioning" Harvard Medical AI | Rajpurkar Lab 24:07 2 years ago 181 Далее Скачать
MDETR: Modulated Detection for End-to-End Multi-Modal Understanding Microsoft Research 1:13:28 3 years ago 2 282 Далее Скачать
Harvard Medical AI: Sameer Sundrani presents "Oscar: ... Pre-training for Vision-Language Tasks" Harvard Medical AI | Rajpurkar Lab 17:22 2 years ago 471 Далее Скачать
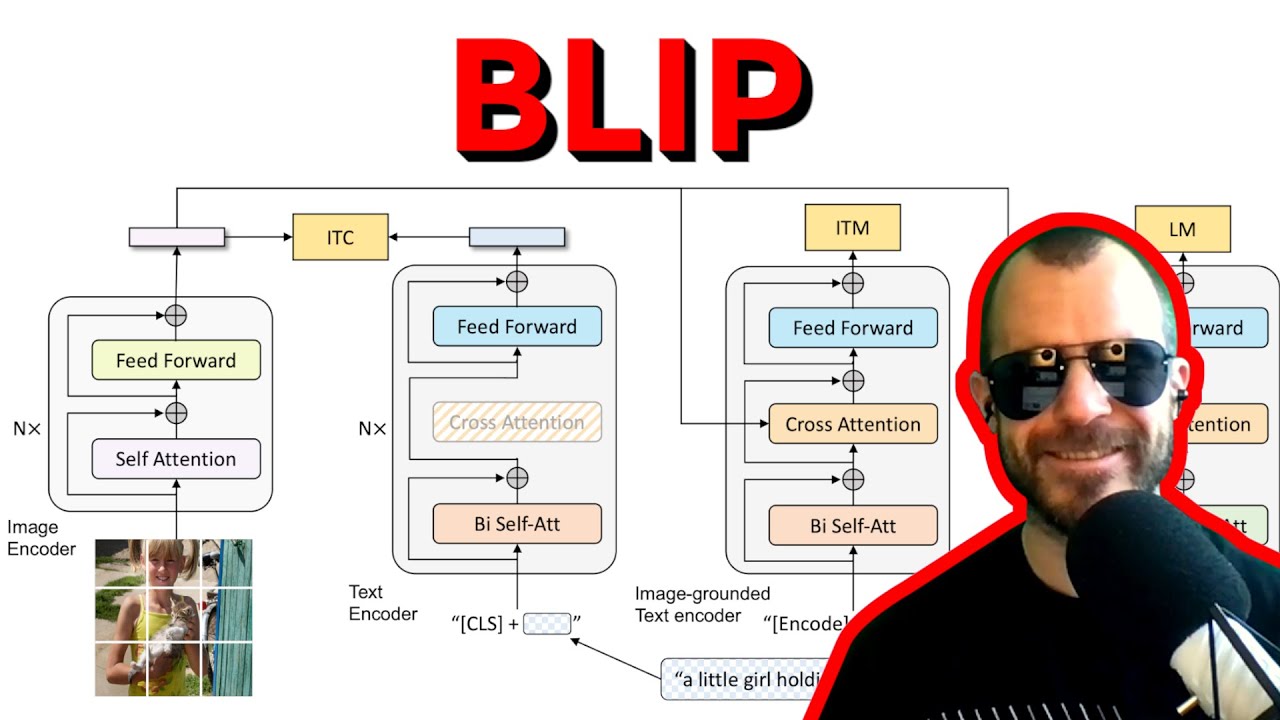
BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding&Generation Yannic Kilcher 46:41 2 years ago 29 686 Далее Скачать
Scaling Language-Image Learning in 100 Languages with PaLI Google Research 11:12 2 years ago 2 995 Далее Скачать